


Introduction to Buffer Overflow Attacks
In today’s blog, we will be taking a very high-level look at buffer overflow attacks.
Attackers exploit buffer overflow vulnerabilities by overwriting the memory of an application. By doing so, an attacker can change the execution flow of the program, thereby instructing the program to execute code stored in an area of memory the attacker controls.
Consider the very basic C code in Figure 1. When the program runs, it asks the user to enter an argument (line 4). The argument entered by the user is then copied to the buffer array (line 13). The buffer array is declared in the main function (line 6) and can store 10 bytes. However, there is no input sanitization, so what happens if an attacker were to enter an argument containing more than 10 bytes? If an attacker were to pass an argument to the program with say 20 bytes, where would the additional 10 bytes go?
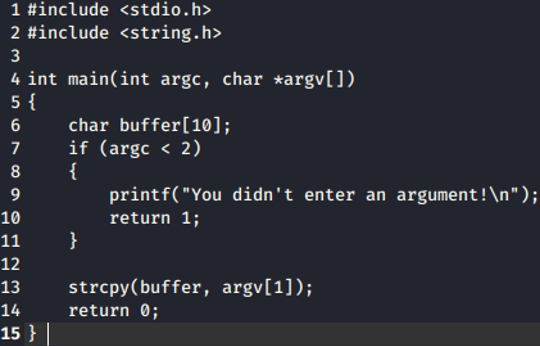
In order to answer the above questions, we first need to talk about memory, and specifically, the stack. The stack is a region of memory that stores short term data for functions i.e. local variables and program control information, such as the ‘return address’, for example. When the C program calls the main function, it must know which address to return to once the function completes. This “return address” is stored in the stack.
Data is passed to and from the stack by several CPU registers. These registers are small, high-speed CPU storage locations where data can be efficiently read or manipulated. Below are three of the most important:
- Stack pointer (ESP): register containing the address of the top of the stack
- Base pointer (EBP): register containing the address of the bottom of the stack frame
- Instruction pointer (EIP): register containing the address of the instruction to be executed
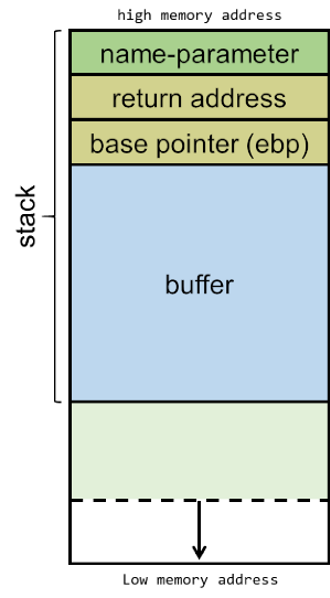
So back to the original question, if the buffer overflows, where do the remaining bytes go? Well, as you can see in Figure 2, if the attacker overflows the buffer, they will be able to overwrite the ‘base pointer’ and the ‘return address’.
Now that we’ve discussed the stack, let’s return to the C program from Figure 1. From the basic code displayed, you can see there are two expected outcomes. If the user runs the program without entering an argument, the program will print an error message advising the user they didn’t enter an argument (line 9), and the function will return an error (line 10). In C code, ‘return 1’ indicates an error, whereas if a function returns ‘0’, the function ran successfully. In this case, the program will finish without an error. Both outcomes are displayed below in Figure 3.
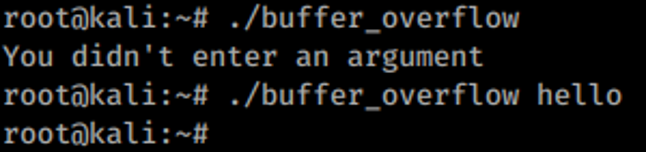
The attacker could overwrite the return address with random code, in order to create a ‘Denial of Service’ condition and crash the program. For example, if an attacker runs the program and passes an argument larger than ten bytes, the program will crash, as demonstrated in Figure 4.

The reason the program crashed is because the buffer array was only meant to hold ten characters. The remaining A’s have overflowed the buffer and have filled the return address. The return address will become the EIP when the function returns. The return address is now full of A’s or “x41”, which is the hexadecimal representation of the letter A. Therefore, the instruction pointer is looking in the memory address “x41x41x41x41”, which is either empty or contains random junk. Therefore, the program doesn’t know what to do next and crashes.
Another option for an attacker would be to overwrite the instruction pointer with an address in memory the attacker has write access to, therefore controlling what the program does next. For example, the attacker could point the instruction pointer to an area in memory containing malicious shellcode, thus giving the attacker control of the victim’s machine, which we will cover in a later series on this topic.
Preventing Buffer Overflow Attacks
This buffer overflow attack could have been prevented by using input validation. Input validation is performed to ensure only properly formed data is entering the workflow of an information system. Checks should be done to make sure input matches the acceptable length, type, and content that is expected by the program. In the code used in Figure 1, a different function could have been used instead of strcpy, which is considered insecure. An alternative option could be to use a function called ‘strncpy’, which is considered by some to be a safer option because you must also pass the maximum length the destination buffer can accept (albiet strncpy has its own shortcomings). This blog won’t go into the different nuances between the two functions.
Other, more advanced mitigation techniques for buffer overflow attacks include ASLR and DEP. Address Space Layout Randomization (ASLR) is a technology used to help prevent shellcode from being successful. It does this by randomly offsetting the location of modules and certain in-memory structures. ASLR randomizes the bases address of loaded applications and DLLs every time the operation system is booted.
Data Execution Prevention (DEP) prevents certain memory sectors, e.g. the stack, from being executed. When these two controls are combined, it becomes exceedingly difficult to exploit vulnerabilities in applications using shellcode or return-oriented programming (ROP) techniques.
Conclusion
Buffer overflow attacks have been around for decades, and it is important for security professionals and software developers to have a basic understanding of how they work, in order to be able to defend against them effectively. We hope this brief, albeit very basic, introduction has been helpful and we will look to go into more detail in a future blog.

